KTransformers + LLaMA-Factory + SGLang:低成本本地超大模型微调与推理
在本地工作站上做大模型实验,难点往往不在写出训练脚本,而在有限预算下把大规模 MoE 模型接进自己的数据、评测和应用原型里。很多团队只是想验证一个垂直数据集、调一版产品 demo,或跑一轮 benchmark,结果先遇到的是显存不够、CPU/内存该怎么配、整机成本是否扛得住。本文从这个场景出发,展示如何把 KTransformers、LLaMA-Factory 与 SGLang 组合成一条面向低成本、低显存的训推一体化流程:LLaMA-Factory 组织 LoRA 微调,KTransformers 通过 GPU+CPU 异构执行降低显存门槛,SGLang 承接后续推理服务和 benchmark。

在架构上,LLaMA-Factory 位于用户最直接接触的编排层,负责数据、模板、LoRA 配置、checkpoint 输出,以及早期的 chat/API 验证入口。KTransformers 接在更底层,作为 Attention/MoE 算子的 LoRA backend engine,把显存压力最大的 expert 计算放到 GPU+CPU 异构路径里,同时尽量保留 LLaMA-Factory 原有的使用方式。SGLang 则负责推理侧,把训练好的 adapter 接入服务化推理、批量请求和 benchmark。
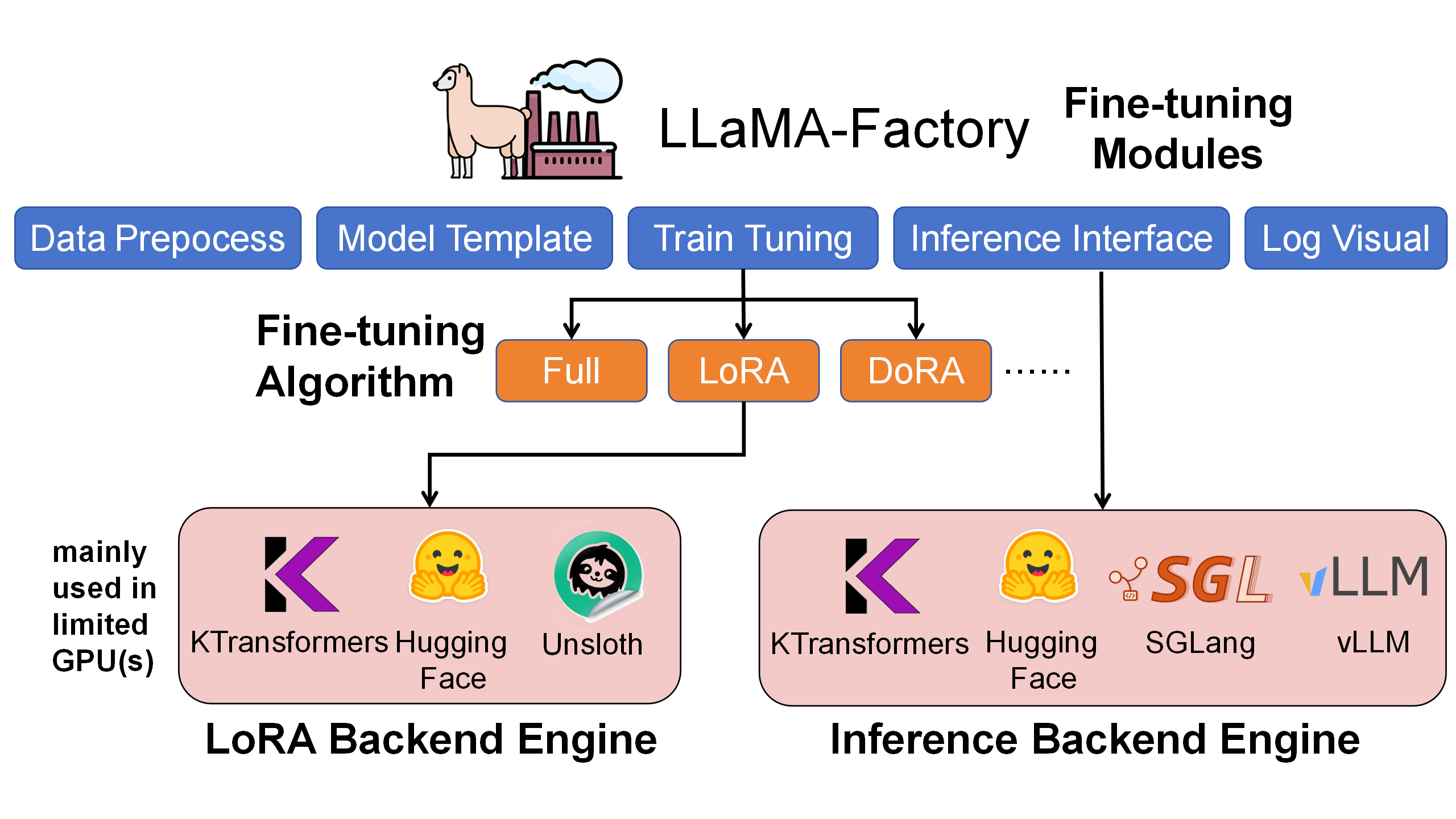
为什么这个集成重要
在同一套 LLaMA-Factory LoRA 微调流程下,我们对比了 HuggingFace、Unsloth 和 KTransformers 三种后端。KTransformers 的重点不是把所有参数塞进 GPU,而是把 MoE 模型拆到更适合的 CPU/GPU 异构执行路径里;因此在 4090 级硬件上,它可以把更大的 MoE 模型纳入本地实验范围。对 DeepSeek-V2-Lite 这类较小 MoE 模型,它也能带来更高吞吐和更低 GPU 显存占用。
| LoRA BF16 + NekoQA-10K 风格化对话 | HuggingFace Backend | Unsloth Backend | KTransformers Backend |
|---|---|---|---|
| DeepSeek-V2-Lite 14B LoRA 微调吞吐 | 303.58 token/s | 455.37 token/s | 530.38 token/s |
| DeepSeek-V2-Lite 14B GPU 显存 | 32.12 GB | 9.64 GB | 6.08 GB |
| DeepSeek-V3 671B LoRA 微调吞吐 | 过大,无法运行 | 不支持 | 40.35 token/s |
| DeepSeek-V3 671B GPU 显存,跨 GPU 求和 | 理论值 1400 GB | 不支持 | 70 GB 实测峰值 |
这里的 1400 GB 指 FP16 全参数常驻显存的理论需求,并不是一套可运行配置。70 GB 是 KTransformers 策略下的实测峰值:Attention 放在 GPU 上,MoE expert 负载按放置策略转到 CPU 侧执行。

微调效果
我们用三个代表性任务观察微调后的变化:
- 风格化对话:基于 NekoQA-10K,让模型更一致地保持目标人格和称呼方式。
- 翻译风格生成:使用夸张的 Westernized translation tone,观察模型是否能学到特定写作风格。
- 医疗问答:使用 AfriMed-QA 的短答案与选择题任务,观察垂直领域微调后的指标变化。
在风格化对话任务中,微调后的模型比 base model 更容易保持目标语气和称呼习惯。
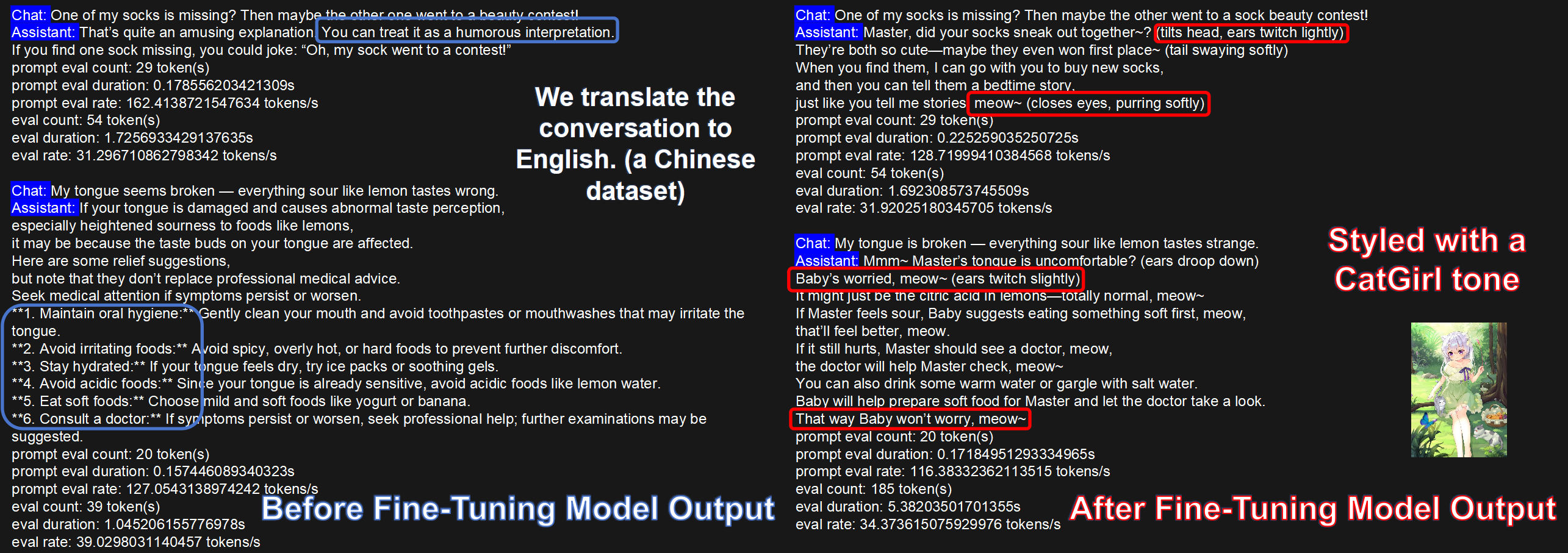
在 Translational-Style 任务上,DeepSeek-V2-Lite 和 DeepSeek-V3 经过 KT-LoRA 微调后,指标都有明显提升。
| Translational-Style dataset | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|---|---|---|---|
| V2-Lite,no LoRA | 20.66 | 8.33 | 4.54 | 2.89 | 22.71 | 4.52 | 19.19 |
| KT-LoRA fine-tuned V2-Lite | 35.41 | 22.44 | 15.42 | 11.18 | 42.03 | 18.38 | 33.10 |
| V3 base,no LoRA | 8.49 | 3.34 | 1.62 | 0.96 | 15.91 | 2.55 | 10.07 |
| KT-LoRA fine-tuned V3 | 37.02 | 23.70 | 16.21 | 11.49 | 43.43 | 18.96 | 34.54 |
在 AfriMed-QA 上,KT-LoRA 也提升了短答案生成指标和选择题准确率。
| AfriMed-QA short answer | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|---|---|---|---|
| V2-Lite,no LoRA | 13.58 | 11.12 | 9.10 | 7.23 | 22.48 | 7.81 | 11.73 |
| KT-LoRA fine-tuned V2-Lite | 35.90 | 27.63 | 22.99 | 19.15 | 35.25 | 17.50 | 28.44 |
| V3 base,no LoRA | 12.75 | 10.27 | 8.05 | 5.99 | 20.33 | 5.65 | 10.11 |
| KT-LoRA fine-tuned V3 | 42.42 | 34.12 | 28.95 | 24.54 | 41.97 | 22.37 | 33.28 |
| AfriMed-QA multiple choice | Accuracy |
|---|---|
| V2-Lite,no LoRA | 0.0645 |
| KT-LoRA fine-tuned V2-Lite | 0.4812 |
| V3 base,no LoRA | 0.5833 |
| KT-LoRA fine-tuned V3 | 0.7930 |
这些结果来自小规模代表性评测,不是完整的 scaling law 研究。它们主要说明:在 LLaMA-Factory 这套大家熟悉的训练入口里,KTransformers 可以把一部分原本超出工作站 GPU 显存范围的 MoE 模型纳入 LoRA 适配流程。
快速开始 [May be outdated, please refer to the newest blog]
如果只关心推理,可以看 1、2、5;如果要把 LoRA 微调和后续推理一起跑通,请按 1 到 5 依次配置。
1. 硬件要求
可以先按任务目标估算资源:
- 只做推理时,CPU 要求相对低一些,但内存决定能不能放下模型权重和上下文。
- 做 KT LoRA 微调时,CPU 必须支持 Intel AMX。可用
lscpu | grep -i amx || true检查。 - GPU 显存决定能放多少 GPU experts 来提速。KTransformers 的价值,是把“显存不够”这个硬限制,拆成内存、CPU 算力和放置策略可以一起调的问题。
| 模型 | KT 推理,粗略起步配置 | KT 微调参考 |
|---|---|---|
| DeepSeek-V2-Lite-14B | 3 GB 显存 + 15 GB 内存 | 6 GB 显存 + 30 GB 内存 |
| Qwen3-30B-A3B | 3 GB 显存 + 30 GB 内存 | 5 GB 显存 + 60 GB 内存 |
| Qwen3-235B-A22B | 9 GB 显存 + 225 GB 内存 | 18 GB 显存 + 450 GB 内存 |
| DeepSeek-V3-671B | 35 GB 显存 + 0.65 TB 内存 | 70 GB 显存 + 1.3 TB 内存 |
2. 环境安装与模型准备
这条流程会用到三层组件:KTransformers 负责异构执行,SGLang 负责服务化推理,LLaMA-Factory 负责把微调配置组织成清晰的训练配方。
# KTransformers 推理内核路径。
git clone https://github.com/kvcache-ai/ktransformers.git
cd ktransformers
cd kt-kernel
./install.sh
# 与 KTransformers 配套使用的 SGLang。
git clone https://github.com/kvcache-ai/sglang.git
cd sglang
pip install -e "python[all]"
# LLaMA-Factory。
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]" --no-build-isolation
# KTransformers 微调依赖。
conda install -y -c conda-forge libstdcxx-ng gcc_impl_linux-64
conda install -y -c nvidia/label/cuda-11.8.0 cuda-runtime
# 为避免本地编译,优先使用与 Python、PyTorch、CUDA、ABI 匹配的 whl。
pip install ktransformers-0.4.2+cu128torch27fancy-cp311-cp311-linux_x86_64.whl
pip install flash_attn-2.8.3+cu12torch2.7cxx11abiTRUE-cp311-cp311-linux_x86_64.whl
pip install transformers==4.56.0
KT 微调需要 BF16 模型权重。以 DeepSeek-V3-671B 为例,公开权重经常以 FP8 形式发布;训练前需要直接下载 BF16 checkpoint,或者先把 FP8 权重转成 BF16。
pip install -U huggingface_hub==0.34.0
huggingface-cli download --resume-download \
Qwen/Qwen3-235B-A22B-Instruct-2507 \
--local-dir /path/to/Qwen3-235B-A22B-Instruct-2507-BF16
3. 使用 KTransformers 进行 LoRA 微调
训练命令本身很短,真正会随实验变化的部分主要写在 LLaMA-Factory 的 YAML 里。
cd LLaMA-Factory
USE_KT=1 llamafactory-cli train examples/train_lora/qwen3moe_lora_sft_kt.yaml
YAML 里最关键的 KT 字段是 use_kt、kt_optimize_rule、cpu_infer 和 chunk_size。kt_optimize_rule 要根据模型、CPU backend 和 GPU 数选择对应的 *-sft-* 规则文件。
### model
model_name_or_path: /path/to/Qwen3-235B-A22B-Instruct-2507-BF16
trust_remote_code: true
template: qwen3
### method
stage: sft
do_train: true
finetuning_type: lora
lora_rank: 8
lora_alpha: 32
lora_dropout: 0.1
lora_target: all
### dataset
dataset: identity, alpaca_en_demo
cutoff_len: 2048
max_samples: 100000
overwrite_cache: true
preprocessing_num_workers: 16
dataloader_num_workers: 4
### output
output_dir: saves/qwen3moe_lora_sft_kt
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true
save_only_model: false
report_to: none
### train
per_device_train_batch_size: 1
gradient_accumulation_steps: 8
learning_rate: 1.0e-4
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000
### ktransformers
use_kt: true
kt_optimize_rule: examples/kt_optimize_rules/<model>-sft-amx-<gpu-count>.yaml
cpu_infer: 64
chunk_size: 2048
训练结果会写入 output_dir,通常包括 safetensors adapter 权重和 adapter metadata。后面的推理步骤会继续使用这个目录。
4. 用 LLaMA-Factory 快速验证
微调刚结束时,建议先用 LLaMA-Factory 做一次快速交互验证:确认 adapter 能正常加载,也看看目标风格或能力是否已经出现。这一步只是训推链路里的轻量检查,不追求最高吞吐。
cd LLaMA-Factory
llamafactory-cli chat examples/inference/qwen3moe_lora_sft_kt.yaml
推理 YAML 需要同时指向 base model 和 adapter 目录,设置 infer_backend: ktransformers,并让 kt_optimize_rule 与训练时使用的 KT 路径匹配。
model_name_or_path: /path/to/Qwen3-235B-A22B-Instruct-2507-BF16
adapter_name_or_path: saves/qwen3moe_lora_sft_kt
template: qwen3
infer_backend: ktransformers
trust_remote_code: true
use_kt: true
kt_optimize_rule: examples/kt_optimize_rules/<model>-infer-amx-<gpu-count>.yaml
cpu_infer: 64
chunk_size: 2048
如果还想继续用 LLaMA-Factory 做批量评测,也可以用同一份配置启动 API:
API_PORT=8000 llamafactory-cli api examples/inference/qwen3moe_lora_sft_kt.yaml
5. 用 SGLang 做推理与 Benchmark
如果要跑更大规模的 benchmark,或者把模型接成应用 API,建议使用 SGLang 服务。流程分三步:先转换 LoRA adapter,再按需要量化 CPU 侧权重,最后在 launch_server 里打开 KT 和 LoRA。
cd sglang
python convert_lora.py <YOUR_LORA_ADAPTER_PATH>
cd ktransformers/kt-kernel
python scripts/convert_cpu_weights.py \
--input-path <PATH_TO>/Qwen3-30B-A3B-Instruct-2507 \
--input-type bf16 \
--output <PATH_TO>/Qwen3-30B-A3B-Instruct-2507-INT8 \
--quant-method int8
python -m sglang.launch_server \
--host 0.0.0.0 \
--port 10103 \
--model <PATH_TO>/Qwen3-30B-A3B-Instruct-2507 \
--mem-fraction-static 0.7 \
--chunked-prefill-size 2048 \
--served-model-name Qwen3-30B-A3B-Instruct-2507 \
--tensor-parallel-size 1 \
--kt-method AMXINT8 \
--kt-weight-path <PATH_TO>/Qwen3-30B-A3B-Instruct-2507-INT8 \
--kt-cpuinfer 64 \
--kt-threadpool-count 2 \
--kt-num-gpu-experts 1 \
--enable-lora \
--lora-paths lora0=<YOUR_ADAPTER_PATH> \
--max-loras-per-batch 1 \
--lora-backend triton
如果只推理 base model,删掉最后几行 LoRA 参数即可。Kimi K2、MiniMax M2/M2.1 等新模型涉及 FP8 或 INT4 原精度推理时,请同步参考 KTransformers V0.5.0 及后续版本说明。
服务启动后,可以用兼容 OpenAI 的 API 调用:
from openai import OpenAI
client = OpenAI(base_url="http://localhost:10103/v1", api_key="EMPTY")
resp = client.completions.create(
model="Qwen3-30B-A3B-Instruct-2507",
prompt="使用 C++、Python 和 Rust 写一个快速排序。",
max_tokens=256,
)
print(resp.choices[0].text)
KT 调参入口
微调侧优先看 kt_optimize_rule。规则文件名通常会写明模型族、是否用于 SFT、CPU backend(如 AMX)以及 GPU 数。在 LLaMA-Factory YAML 里,用户一般只需要关注 use_kt、kt_optimize_rule、cpu_infer、chunk_size 这四个 KT 字段。
SGLang 服务侧可以按这个顺序排查显存压力:prefill OOM 先调小 --chunked-prefill-size,decode OOM 先降低 --max-running-requests,GPU experts 常驻过高时减少 --kt-num-gpu-experts,CPU 内存或带宽吃紧时把 CPU 权重量化为 INT8,最后再根据压测目标微调 --mem-fraction-static。
性能与内存
报告实验中设置了 GAS=16、qlen=512,所以每个 optimization step 会处理 8192 tokens。
| Model | Step time | Tokens per step | Throughput |
|---|---|---|---|
| DeepSeek-V3 671B | 203 s | 8192 | 40.35 token/s |
| DeepSeek-V2-Lite 14B | 36 s | 8192 | 227.6 token/s |
对应的实测内存占用如下:
| Model | GPU memory | Host memory |
|---|---|---|
| DeepSeek-V3 671B,61 层中 58 层为 MoE | 跨 GPU 合计约 70 GB | 约 1.2-1.3 TB |
| DeepSeek-V2-Lite 14B,27 层中 26 层为 MoE | 约 5.5 GB | 约 150 GB |
技术说明
本节压缩整理自原 Developer Technical Notes。凡标注 Deprecated in V2 Current 的内容,都来自早期技术说明,只保留为历史实现背景。
Attention with LoRA
KTransformers 提供 operator injection,也就是 BaseInjectedModule;PEFT 提供 LoRA layer insertion。为了让二者一起工作,原技术说明中设计了 KTransformersLinearLora,它同时继承 KTransformersLinear 和 LoraLayer。
这样一来,prefill_linear / generate_linear 这类 KT 高性能路径可以继续使用,同时也能接入 LoRA 参数 lora_A / lora_B。准备阶段会把原始 KTransformersLinear 层替换为 KTransformersLinearLora,让 Q/K/V/O linear transforms 仍走 KT 优化路径,并具备 LoRA 可训练性。
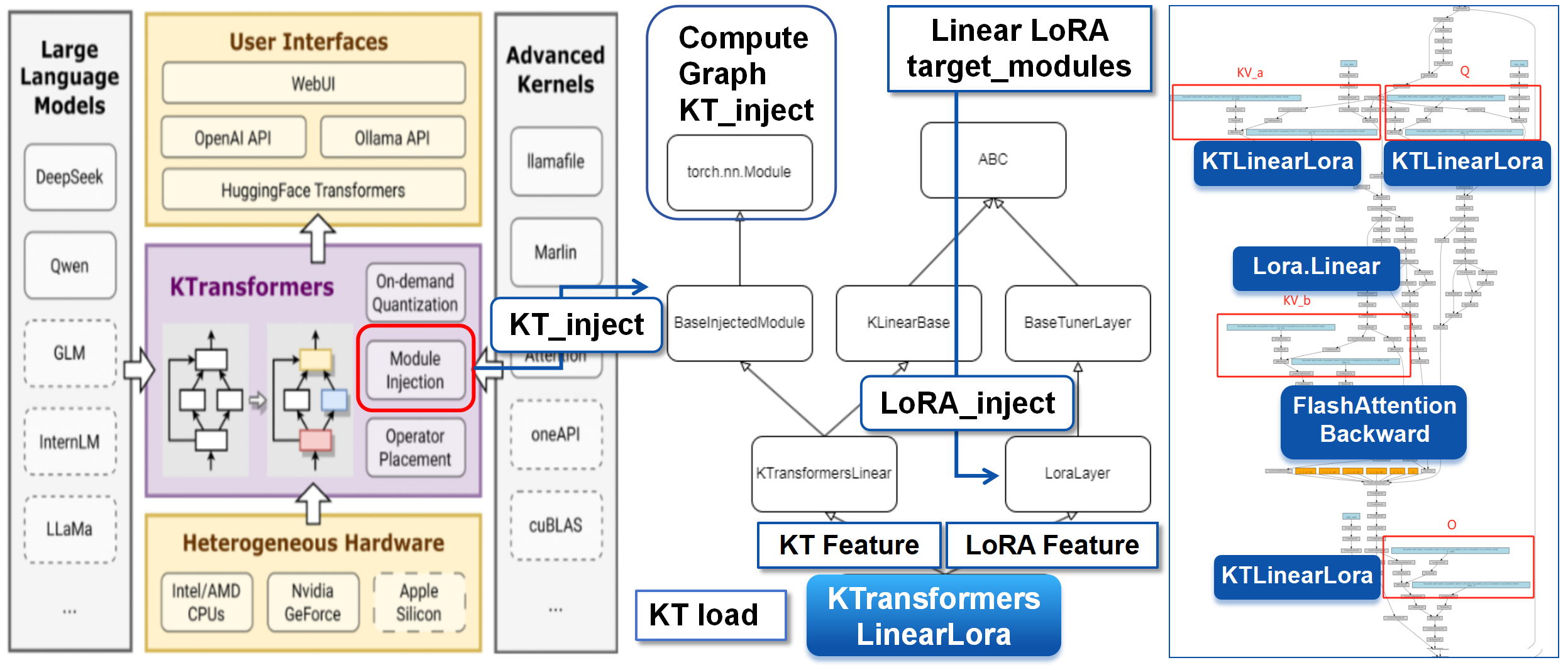

MoE as a Differentiable Backend Operator
MoE 参数量大、计算又是稀疏的。原技术说明把 expert computation 封装成一个 differentiable black-box operator:对上游 PyTorch graph 来说,它只是一个 compact autograd node;对下游 backend 来说,Autograd Function 内部再通过 pybind11 调用 C++ extensions 完成 forward/backward。
后端可以通过 YAML 切换。原评测路径覆盖 AMX BF16/INT8,也包括 llamafile-style CPU kernels。

MoE Backward (CPU) (Deprecated in V2 Current)
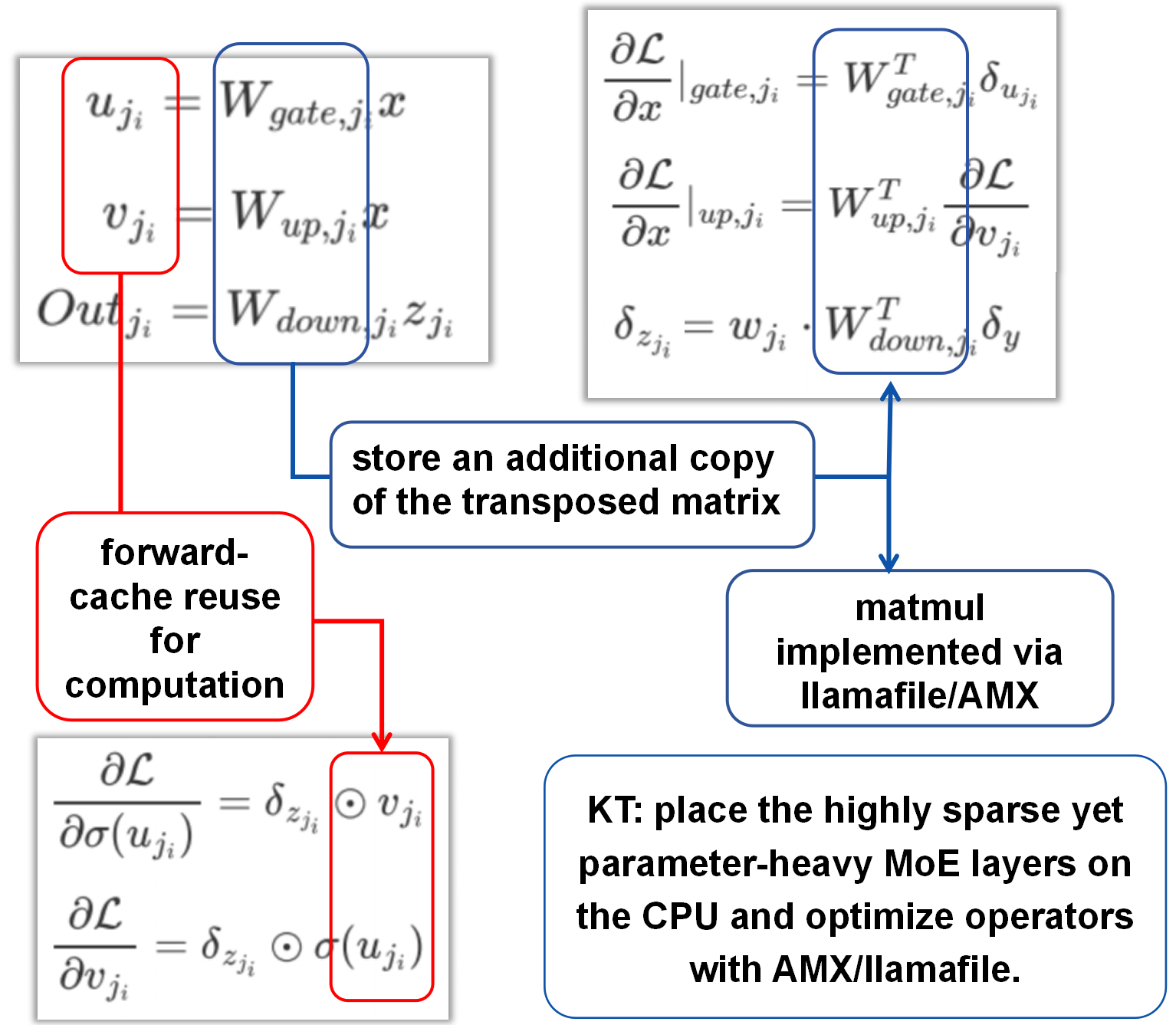
Deprecated in V2 Current. 原技术说明提到,MoE backward 经常需要转置权重 $W^\top$。为了避免运行时反复 transpose,早期实现会在 load time 预先计算并缓存 $W^\top$。这种“额外保存一份转置矩阵 copy”的实现细节在 V2 current 中已经过时,本段仅作为历史背景保留。
原技术说明还提到,会缓存必要的中间激活,例如 expert projections,供 backward 复用,减少 recomputation。除非重新对照当前 V2 实现验证,否则这一小节都应按历史说明理解。
Multi-GPU Loading/Training: Placement Strategy Instead of DataParallel (Deprecated in V2 Current)
Deprecated in V2 Current. 本小节里的 KTrainer、explicit placement 和 DataParallel avoidance 细节来自原 Developer Technical Notes,不代表当前 V2 行为。这里保留它们,只是为了交代早期设计背景。
在原技术说明中,多 GPU strategy 依赖 explicit placement 加 model parallelism:
- Deprecated in V2 Current:
KTrainer接管.to(device),避免把整个模型搬到单张 GPU 上。 - Deprecated in V2 Current: 使用 KT optimize-rule YAML,让每一层声明
device: cuda:0/cuda:1/...,并直接在目标 GPU 上构造。 - Deprecated in V2 Current: 当
USE_KT=1时,禁用 LLaMA-Factory/HF Trainer 的 automatic DataParallel wrappers,避免整模型复制。 - Deprecated in V2 Current: gradients reduce 到
cuda:0;intermediate activations 尽量留在本地,只传必要 tensors。
Deprecated in V2 Current. 原技术说明把 DeepSeek-671B 的典型方案描述为:KV/attention parts 放在 GPU 上,MoE experts 在 CPU 上 sharding,并由多张 GPU 分担工作量,从而降低 per-GPU memory peak。这个具体的 placement/trainer 描述在 V2 current 中已经过时。
局限性
目前多数测试仍集中在单一数据集和小规模数据上,通常不超过 20k examples。本文主要说明 KT-LoRA 微调系统能够跑通并带来可观察的效果,而不是给出关于泛化能力、scaling law、多 seed 方差或多语言鲁棒性的完整算法结论。
我们欢迎社区补充更多测试结果,尤其是同时提供 KT config、dataset examples、training/evaluation YAML、GPU memory、CPU memory、CPU 型号和 backend 细节。这类信息更方便横向比较,也更有社区参考价值。
结论
KTransformers、LLaMA-Factory 与 SGLang 组合起来,为超大 MoE 模型提供了一条低成本、低显存的训推端到端路径:LLaMA-Factory 统一训练配方,LoRA 降低定制成本,KTransformers 提供异构 placement 与 Attention/MoE operator 优化,SGLang 承接 benchmark 和应用推理。
对较小 MoE 模型,这条路径可以降低 GPU 显存并提升吞吐;对 671B 级超大 MoE 模型,它提供了默认全 GPU 训练之外的另一种选择。